在当今大数据时代,数据的爆炸式增长对存储和处理能力提出了巨大挑战。HDFS(Hadoop Distributed File System)作为大数据生态系统的核心组件,以其高容错、高吞吐的特性成为分布式存储领域的标杆。
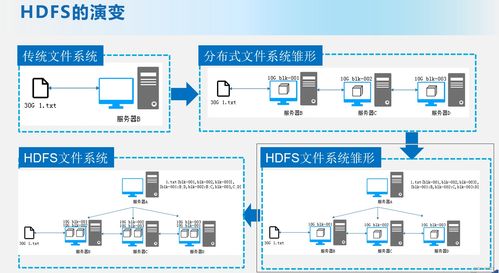
HDFS采用主从架构设计,由NameNode和DataNode组成。NameNode作为管理节点,负责维护文件系统的命名空间和元数据;而多个DataNode则负责实际的数据存储。这种设计使得HDFS能够有效管理PB级别的数据,并在成百上千台廉价服务器上稳定运行。
在数据存储机制方面,HDFS将大文件分割成固定大小的数据块(默认为128MB),并在不同节点间进行多副本冗余存储。这种机制不仅提高了数据读写效率,还确保了数据的可靠性。当某个节点发生故障时,系统能够自动从其他副本恢复数据,实现无缝故障转移。
对于大数据服务而言,HDFS提供了完善的API接口,支持多种编程语言进行数据操作。无论是批处理作业还是实时分析,HDFS都能提供稳定可靠的数据支撑。其优秀的横向扩展能力使得企业可以根据业务需求灵活调整存储规模。
值得注意的是,在实际部署HDFS时,需要特别注意参数配置和集群监控。合理的块大小设置、副本因子配置以及定期的NameNode元数据备份都是确保系统稳定运行的关键。随着技术的发展,HDFS也在不断演进,正与云计算、容器化等新技术深度融合,为各类大数据应用提供更强大的存储支撑。
总而言之,HDFS作为大数据基础设施的重要组成部分,其分布式架构和容错机制为海量数据的存储和管理提供了可靠的解决方案,是大数据服务不可或缺的技术基础。